Facial Events Discovery
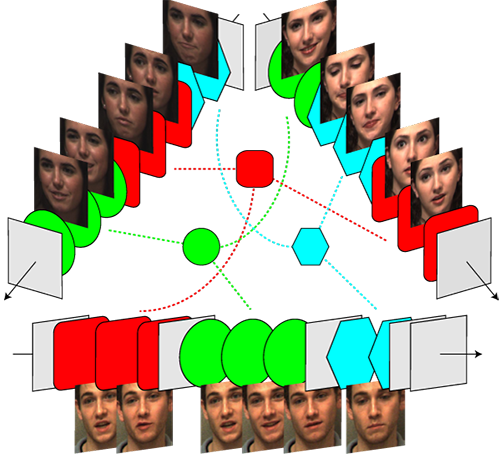
Selected video frames of unposed facial behavior from three participants.
Different colors and shapes represent dynamic events discovered by unsupervised learning: smile (green circle) and lip compressor (blue hexagons). Dashed lines indicate correspondences between persons.
People
- Feng Zhou (CMU)
- Fernando De la Torre (CMU)
- Jeffrey F. Cohn (UPitt)
Introduction
Automatic facial image analysis has been a long standing research problem in computer vision. A key component in facial image analysis, largely conditioning the success of subsequent algorithms (e.g., facial expression recognition), is to define a vocabulary of possible dynamic facial events. To date, that vocabulary has come from the anatomically-based Facial Action Coding System (FACS) or more subjective approaches (i.e. emotion-specified expressions). The aim of this paper is to discover facial events directly from video of naturally occurring facial behavior, without recourse to FACS or other labeling schemes. To discover facial events, we propose a novel temporal clustering algorithm, Aligned Cluster Analysis (ACA)[2] [3], and a multi-subject correspondence algorithm for matching expressions. We use a variety of video sources: posed facial behavior (Cohn-Kanade database), unscripted facial behavior (RU-FACS database) and some video in infants. ACA achieved moderate intersystem agreement with manual FACS coding and proved informative as a visualization/summarization tool.
Result of a Baby Facial Sequence
This video shows a sequence of baby facial behavior used in the second and third video shown below.
Download the [Video 3.5MB].
This video shows the facial landmark localization and the geometrical features used by our methods.
Download the [Video 3.5MB].
Our method divides the input baby facial sequence into five clusters (columns) of temporal segment. Each cluster (column) corresponds to a particular facial event.
Download the [Video 3.5MB].
Our method offers an efficient video retrieval mechanism. Given a query video, our method efficiently matches it to the video segments using a dynamic time warping based similarity (red bar).
Download the [Video 3.5MB].
Result on Benchmark Datasets
Given a synthetic sequence by concatenating several videos from the Cohn-Kanade dataset, our method can find the coherent temporal clusters of different facial events as well as their low-level embeddings.
Download the [Video 3.5MB].
Given a synthetic sequence by concatenating several videos from the Cohn-Kanade dataset, our method can find the coherent temporal clusters of different facial events as well as their low-level embeddings.
Download the [Video 3.5MB].
Publications
-
[1]Unsupervised Discovery of Facial EventsIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2010, Oral
F. Zhou, F. De la Torre and J. F. Cohn
References
-
[2]Aligned Cluster Analysis for Temporal Segmentation of Human MotionInternational Conference on Automatic Face and Gesture Recognition (FG), 2008
F. Zhou, F. De la Torre and J. K. Hodgins[Paper 1MB] -
[3]Hierarchical Aligned Cluster Analysis for Temporal Clustering of Human MotionIEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), vol. 35, no. 3, pp. 582-596, 2013
F. Zhou, F. De la Torre and J. K. Hodgins[Paper 3MB]